

My initial expectation when looking at video generation was that the AI model would generate new videos from the text descriptions provided, just like the extremely successful images generated in the case of image generation.
ChatGPT plugins
Visla
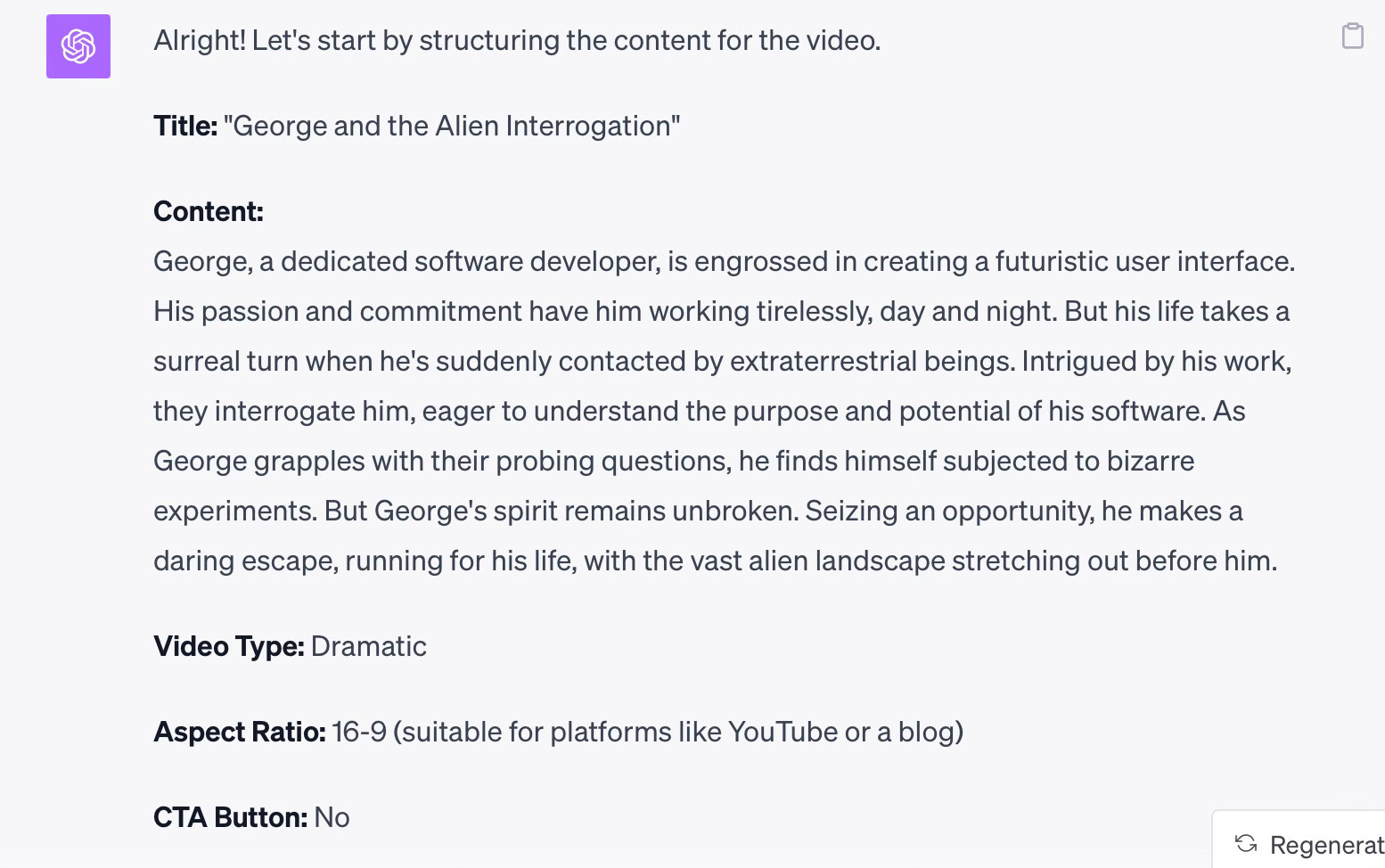
Develop a video with the following summary: George is a software developer who is working day and night, developing software for a futuristic user interface. He is contacted by aliens and interrogated to find out how the software is goiing to be used. They do experiments on him at one point, when he escapes and tries to get away on foot.The plugin expands the video description to make it a better fit for a short video. See the revised script below:

The plugin also provides instructions on how to retrieve the generated video. Initially the generated video uses premium stock and if you do not have a premium membership then the software proposes to use free stock and replaces the scenes to eliminate any premium content.
The resulting video can then be exported and edited or used. This can be done within the Visla web page or another editing program if exported.

The initial implication for a video generating plugin for ChatGPT is that it would create original videos based on the content in the textual prompt, similar to what DALL-E or other applications can use the Diffusion model to generate original images. However, it looks like Visla only uses ChatGPT’s text generation mode to expand the story and then searches for existing video (premium or free) footage to put together the expanded story. This results in a video where the voiceover describes the expanded story but the video scenes are just barely related to the text.
Woxo
I used the same script with another plugin named Woxo. I’m not sure what the background is, but this resulted in a video that basically reads the script and does not produce any footage.
Video AI by Invideo
This is another plugin that creates videos with a textual script/description. It uses stock footage, but I found it more successful than Visla, for example.
Lucas AI
The same type of plugin. Videos are more like sketches, although the narration seems good. It creates four variants of the same video, but the footage is the same, effects and background are somewhat different.
The distinctive feature of this plugin, like all the others is the text it produces from the user prompt. This will make a difference in the production of the video.
CapCut
Similar but somewhat disappointing output. It uses the text as a VoiceOver, but the resulting “video” is a collection of images tied together by a flow and some music.
HeyGen
HeyGen is another plugin to generate video from text. I was not successful in making this work, getting errors constantly.
Other Generators
DeepBrain AI
This application gets a prompt from the user, uses ChatGPT to generate a response to the prompt and then uses a presenter to read the text.
Synthesia
This is the same type of application that generates realistic presentation videos reading the text provided.
The Verdict
I’ve gone through a lot of similar products but I have not been able to find any that can actually create new content similar to what is done for images. I think the reason is the lack of a robust model mapping text to video content. I am waiting for the release of Google’s Gemini model, which is described as a multimodal model and as such could be trained with videos, thus being able to produce videos as well.