

Google
Med-Gemini
Google has published a paper describing Med-Gemini, a Gemini-family model “fine-tuned and specialised for medicine.” It has been trained on a variety of tasks such as advanced reasoning (especially summarising medical notes and creating referral letters), multimodal understanding of medical information and long context understanding (with the chain-of-reasoning technique).
Google claims it beats GPT4-V (vision) and other models in medical tasks (Figure from the paper mentioned above).

Alpha Fold 3
Google Deep Mind and Isomorphic Labs released the new version of the Biology prediction tool Alpha Fold.
Astra
Google has announced a Digital Assistant, Astra, one day after OpenAI unveiled their GPT 4o-model in voice mode. Astra can use captured videos and voice recognition to answer questions in real time. It is using the “Gemini Live” capability.
Gemini
Google’s Gemini model is being integrated into more services such as Gmail and Google Photos. Some AI features are being rolled into the next Android release (15). Google search is getting a lot of AI features such as summaries and more intelligent answers, through a Gemini model optimised for search. Google Photos is going to be able to search for photos in a library based on textual prompts.
Gemini 1.5 Flash is a more lightweight model in the Gemini family and is going to perform better in high-frequency use.
Gemini Nano, the version used on Android phones will get a multi-modal update.
Gemma
Google announced new versions of their open-source Gemma models with a Vision variant PaLI 3, to be released in June.
Veo
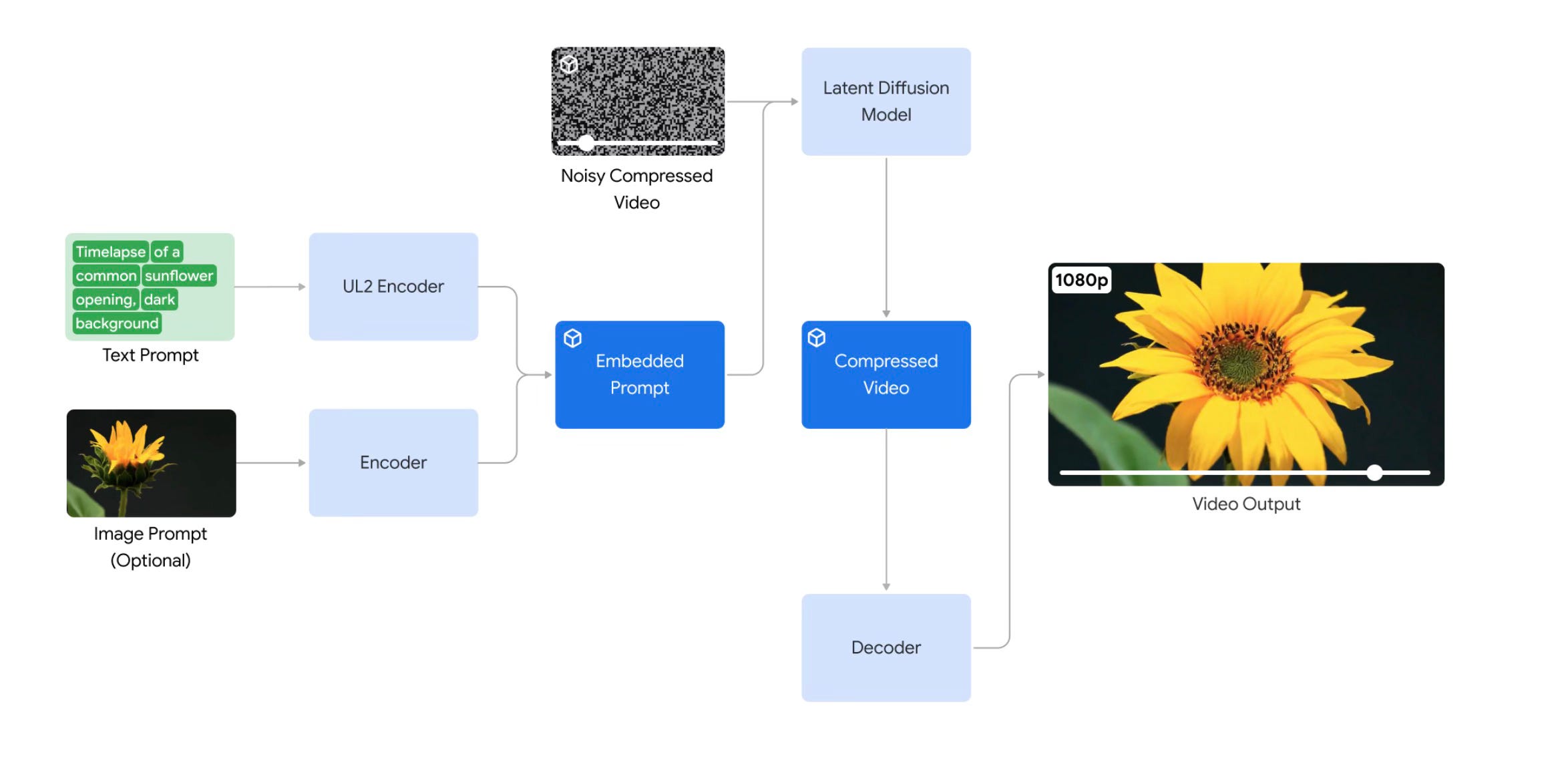
Veo is a new text-to-video generation model released by Google DeepMind. It can generate 1080p videos. Its features will be available soon through VideoFX and there is a waiting list to join to experiment on Veo. At first sight, it seems to match the performance of OpenAI’s Sora model in terms of its style and performance.
Google has also added a figure that explains how Veo works on their site for Veo.
Imagen
Google announced a new version of their Imagen text-to-image model.
Here is an image of Capadoccia, Turkey generated by Imagen 3 (on Google’s site).

Vidu
Researchers from Shengshu Technology and Tsinghua University unveiled Vidu, a text-to-video model and a competitor to OpenAI’s Sora. Vidu can generate 16-second clips at 1080p just from a text prompt. In contrast, Sora can produce clips up to 60 seconds long. Additionally, when comparing the output of Vidu with that of Sora, OpenAI’s model generates higher-quality videos.
Vidu is based on a Universal Vision Transformer (U-ViT) architecture, which the company says allows it to simulate the real physical world with multi-camera view generation. This architecture was developed by the Shengshu Technology team in September 2022 and predates the diffusion transformer (DiT) architecture used by Sora.
Here is a minute-and-a-half video generated by Vidu.
OpenAI
Stackoverflow
OpenAI and StackOverflow have reached a deal where OpenAI will provide Stackoverflow its models to use in its systems whereas Stackoverflow will provide OpenAI to train its systems with programming information.
ModelSpec
OpenAI has released ModelSpec, a set of rules and guidelines for ChatGPT behaviour.
Lawsuits
Another 8 U.S. newspapers have sued Microsoft and OpenAI for their content used in the training of ChatGPT.
Scarlet Johannsen is suing OpenAI since they seem to have used her voice (or something very similar) in the voice support for their GPT-4o model. Apparently she has been contacted by Sam Altman for the permission to use her voice but she refused. OpenAI claims that they used another voice artist.
GPT 4o “Omni”
OpenAI released a new GPT model named GPT 4o (o for “Omni”) which it claims to be much more efficient. Pricing and performance seem to be better than GPT4. An interactive demo was taken positively but raised questions about whether it was a completely genuine performance with no tricks. OpenAI also announced desktop versions of ChatGPT for better performance. After the demo, only text and image input and text output were available. Other modes will be released gradually after some testing.
Board problems
Ilya Sutskever, the OpenAI co-founder and Chief scientist who took part in the “coup” to fire Sam Altman last year has left the company, being replaced by Jakub Pachocki as the new Chief Scientist. OpenAI Safety team leader Jan Leike also left the company, citing differences. It was reported that the whole Safety team was disbanded.
OpenAI formed a new Critical Safety and Security Committee after internal criticisms about the former team being dissolved.
Udio
Udio updated its tools to provide additional music generation functionality. In-painting allows users to edit and refine existing audio tracks, by selecting and re-generating a part of the track based on the surrounding music. Track durations can now be up to 15 minutes. The context window size can be selected to improve musical style consistency or to transition between different styles. The track can now be trimmed before extending it.
Udio is now out of the beta phase and offers a free layer as well as paid layers to allow users to produce more and longer tracks.